



The journey of improving an LLM application is rife with challenges. These include getting properly structured responses (e.g., Pydantic is all you need), creating robust business-specific evaluations (e.g., Your AI Product Needs Evals), building Data flywheels, battling hallucinations, and much more. Rightfully so, these complexities have made it too tempting to improve LLM products via vibe checks alone.
What I've found most interesting, however, is that no one is paying attention to the elephant in the room – Feedback. Feedback is great because it's the only self-generating, absolutely free resource you have to improve your LLM application, and no, I don't mean simple Thumbs up/down. Let's dive in.
What is RLHF and why should I care
Before diving in, let's take a brief walk down memory lane. Although many don't use feedback in their AI systems, no one seems to disagree that feedback, i.e., Reinforcement Learning from Human Feedback (RLHF), caused the current AI boom and rise of ChatGPT.
RLHF involves creating a reward system with human feedback to train foundational models on which responses align better with human preferences. It's the secret sauce that transformed LLMs from glorified auto-completion tools into systems capable of nuanced, context-aware responses.
If you squint hard enough, you may already see something interesting. User Feedback + Few Shot prompting is the poor man's RLHF. At inference time, we can essentially "fine-tune" a model on our users' preferences by providing good examples, and we can identify good examples by letting our users tell us! This is actually great because RLHF is expensive for model providers but free for application builders.
So if OpenAI and Anthropic are spending billions on this, why aren't you doing it for free?
Feedback is all you need
There are three main categories of feedback: explicit, implicit action-based, and implicit acceptance-based. The next section will dive into each type and provide some tactical examples of how you can improve your LLM systems with each.
Types of Feedback
Explicit
Explicit feedback is the prototypical thumbs-up/down good/bad feedback. It can also be based on a scale; the key thing, however, is that you explicitly ask your users for this feedback.
Take the case of Mintlify's AI chat modal from our docs.
When the user submits feedback by clicking one of the thumbs-up/down buttons, you can imagine a function recording the result. You can also save the request data in a test dataset, including the question, the answer, and the feedback.
```python
def collect_explicit_feedback(request, response, score):
if score == "thumbs_up":
save_to_dataset(request, response, score)
```You can then improve your LLM results by fetching examples from your dataset that semantically match the user request and inserting them into the prompt as few-shot examples for the model.
```python
def rag_prompt(question):
examples = fetch_based_on_sematic_similarity(question)
context = fetch_context_from_vector_db(question)
prompt = f"Answer the users question based on the context. Here are some examples of good responses to a similar question. {examples}. Context: {context}. User question: {question}. Answer: "
return make_llm_call(prompt)
```Gotchas
The primary issue with explicit feedback lies in the disconnect between humans and LLMs. LLMs thrive on positive examples, whereas humans are inclined to give feedback when it's negative. As a result, it's hard to collect sufficient information using explicit feedback, which I think is the leading cause for the lack of feedback being used in general. However, there is a better alternative.
Implicit Action based
For most applications, the developer wants the user to take some action, and this is codified. In the world of LLMs, we can say that if our LLM causes our users to take a desired action, this is implicit positive feedback. For example, our LLM recommends to a shopper to buy a particular item, and then later, the user adds that item to the cart.
This type of feedback is potent because it can be enriched with a lot of information in addition to the question and answer. With this new information, we can provide better few-shot examples, which should cause the LLM to give responses more likely to guide the user to positive action.
Here is an example using Parea AI+instructor to capture action-based feedback and dynamically create datasets. Full code here.
```python
def get_recommendations(few_shot_limit: int = 3):
dataset = p.get_collection("Good_Recc_Examples")
testcases = list(dataset.test_cases.values()) if dataset else []
return [testcase.inputs for testcase in testcases[:few_shot_limit]]
# using instructor to generate a typed response
class Recc(BaseModel):
product: Catalog
reason: str = Field(
..., description="Reason response on why you think the user will like this product, phrased as if taking directly to the user using one the following tones [Salesy, Fact focused, Benefit focused, Feature focused, Adamant].",
)
def lmm_product_recommendation_for_user(user_interest: str) -> Recc:
messages = [{"role": "user",
"content": f"Based on the users interests, recommend one
product from our catalog: {CATALOG}. User
interest: {user_interest}"
}]
if recommendations := get_recommendations():
messages.append({
"role": "user",
"content": f"Here are some example recommendations from the
past that the user enjoyed. Your reasoning
should follow this style. Recommendations:
{recommendations}"
})
return client.chat.completions.create(
model="gpt-4o", messages=messages, response_model=Recc
)
@trace
def llm_shopping(user_interest: str) -> Recc:
recc = lmm_product_recommendation_for_user(user_interest)
RECOMMENDATIONS[recc.product.id] = TraceData(
trace_id=get_current_trace_id(),
input=user_interest,
output=recc.model_dump_json()
)
return recc
def shopping_cart_checkout(catalog_item: Catalog):
if catalog_item.id in RECOMMENDATIONS:
trace_data = RECOMMENDATIONS[catalog_item.id]
p.add_test_cases(
[{
"user_interests": trace_data.input,
"recommendation": trace_data.output
}],
name="Good_Recc_Examples",
)
p.record_feedback(FeedbackRequest(
trace_id=trace_data.trace_id,
score=1.0
))
handle_checkout(catalog_item)
```Below, we can see how the few shot examples were injected into our prompt:
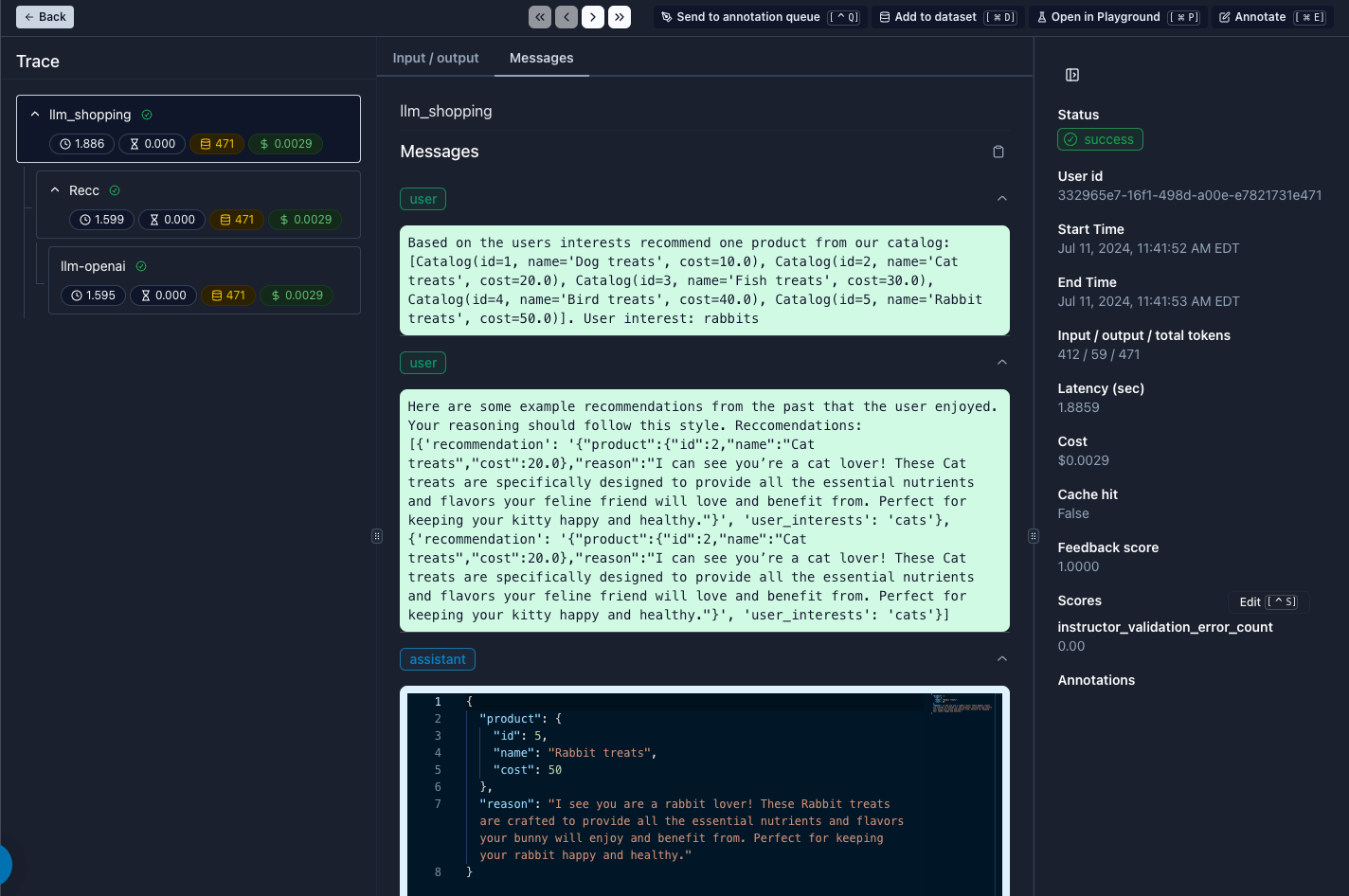
In this example, the trait we want the model to learn is how to "sell" a product. In the LLM recommendation response, we ask the model to try to sell using one of the following tones: [Salesy, Fact-focused, Benefit-focused, Feature-focused, or Adamant]. As you can imagine, over time, one of these tones may be more effective. An automated way to capture this is by leveraging implicit action-based feedback.
Implicit Acceptance Based
Sometimes, an LLM response may propose a solution/alternative to a user. The user can then accept or dismiss it, for example, in copilots or auto-completion. If the user accepts the recommendation, this is a rich value signal.
Conclusion
Feedback can create a flywheel that allows you to iteratively improve your LLM applications. It's often overlooked, but in reality, it's a cheap and powerful way to guide LLM models. Of course, this, too, can get complex, especially as you think more deeply about "how to identify good/relevant few-shot examples." But even the naive approach of grabbing the latest X examples or a random selection should drive improvements. In one of the examples, we used Parea AI; however, feedback collection and few-shot injections are techniques that can be implemented in many ways; choose/build the tool that works for you! I hope this post gives you an intuition on how to creatively view your users' implicit and explicit actions as opportunities to collect feedback.
I'd love to hear from you if you found this post helpful or have any questions. My email is joel@parea.ai.
“To be convinced of one's ignorance is the first and most essential step towards any real knowledge or improvement.” — David Human, A Treatise of Human Nature